Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models
![]()
Abstract
Post-training quantization is the leading method for addressing memory-related bottlenecks in LLM inference, but unfortunately, it suffers from significant performance degradation below 4-bit precision. An alternative approach involves training compressed models directly at a low bitwidth (e.g., binary or ternary models). However, the performance, training dynamics, and scaling trends of such models are not yet well understood. To address this issue, we trained and openly released the Spectra LLM suite consisting of 54 language models ranging from 99M to 3.9B parameters, trained on 300B tokens. Spectra includes FloatLMs, post-training quantized QuantLMs (3, 4, 6, and 8 bits), and ternary LLMs (TriLMs) - our proposed TriLM, which significantly outperforms previously proposed ternary models of a given size (in bits), as well as half-precision and quantized models. For example, TriLM 3.9B is (bit-wise) smaller than the half-precision FloatLM 830M, but matches half-precision FloatLM 3.9B in commonsense reasoning and knowledge benchmarks. However, TriLM 3.9 is also as toxic and stereotyping as FloatLM 3.9B, a model six times larger in size. Additionally, TriLM 3.9B lags behind FloatLM in perplexity on validation splits and web-based corpora but performs better on less noisy datasets like Lambada and PennTreeBank..
Overview of Spectra Suite
The Spectra suite includes comprehensive families of Large language models designed to span different parameter counts and bit-widths. This suite includes three main model families: TriLMs (Ternary Language Model), FloatLMs (F16 Language Model), and QuantLMs (3, 4, 6, and 8 bits quantised FloatLMs). Spectra aims to facilitate scientific research on low-bitwidth LLMs.
The Spectra suite stands out with several key properties:
- Scale: The suite spans a broad spectrum of scales across parameter count and bitwidth.
- Uniform Training: All models are trained using identical data sequences.
- Public Accessibility: The training data is publicly available for study.
- Consistent Model Size Mapping: All models across the family maintain a consistent one-to-one mapping for size.
Each model family within Spectra spans from 99M to 3.9B parameters, covering nearly two orders of magnitude in size. All the TriLMs and FloatLMs are trained on a standardized 300B subset of Slim Pajama data, ensuring training consistency. QuantLMs undergo quantization using the same calibration data, maintaining uniformity in model quantization procedures. Data ordering and batch sizes are also kept consistent within each model family to support reproducibility and comparability in research efforts.
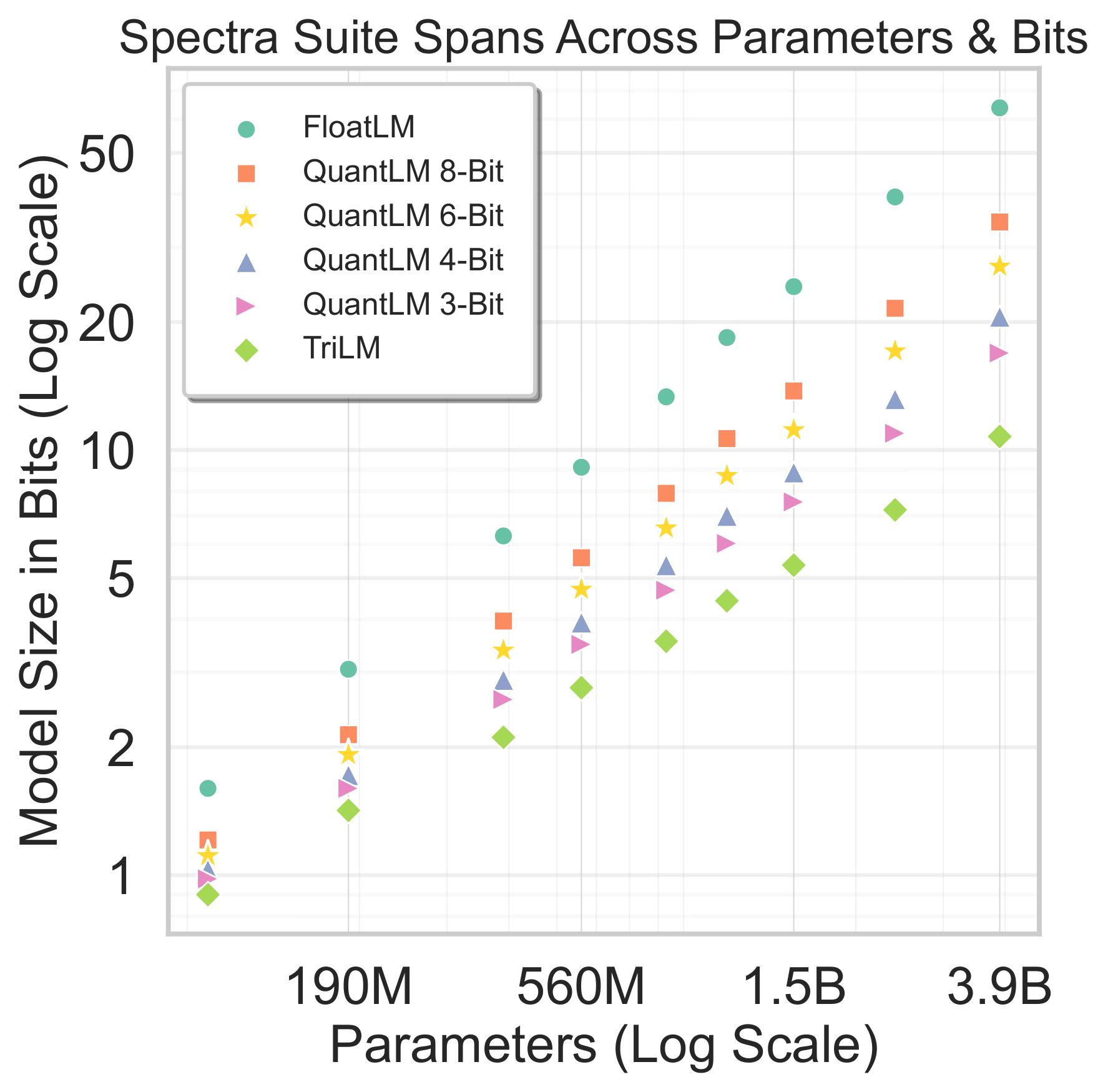
Figure above demonstrates the Spectra LM suite spanning across two dimensions - size (bits) and parameters. For each parameter count, we have 6 models across different bitwidths. Due to availability of FloatLM, Spectra can easily be extended with new QuantLMs by using different Post Training Quantization methods.
Architecture of TriLM and FloatLM
TriLM and FloatLM are both LLaMa-style autoregressive transformers model with RMSNorm instead of LayerNorm, SwiGLU Gated MLP instead of standard transformer MLP, Rotary Position Embedding (RoPE), Multi-Headed Attention and no bias terms.
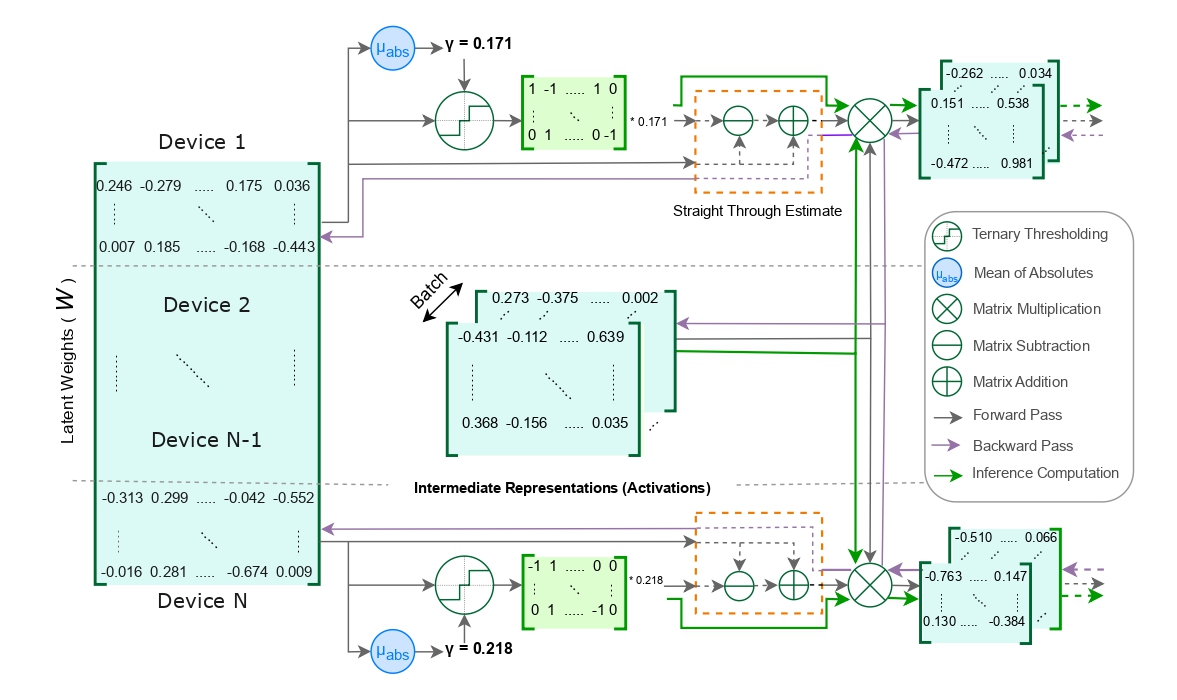
In FloatLMs, the parameters in weight matrix of linear layers are represented as floating point (FP16/BF16) numbers. Whereas, in TriLMs, these parameters are represented in one of three possible ternary states {-1, 0, 1} along with an additional floating point number - `scale’ shared across the matrix. During training of TriLMs, the latent (or master) weights are maintained in floating point precision allowing accumulation of small updates over iterations that eventually contributes to a switch in the estimated ternary state of a parameter. During forward pass of TriLMs, floating point latent weight weights are ternarized on the fly - by first computing setting the scale to the absolute mean of the latent weights, then estimating the ternary state of a parameter by rounding off to the nearest ternary state after scaling. During the backward pass, a straight through estimator is used to estimate backward pass on the floating point latent weights. The computation flow of forward and backward pass of TriLMs is shown in Figure.
QuantLM: Quantisation of FloatLM
We quantized all transformer layer weights. For 3-bit and 4-bit quantization, we employ a group size of 128, which results in effective bit rates of 3.25 and 4.25 bits per parameter, respectively. We’ve refined our approach by incorporating best practices from recent research, particularly in terms of calibration data and scaling it to a million tokens for improved reconstruction. More details are available in the paper.
To ensure a fair comparison with TriLM, we maintain certain components in their original precision. Specifically, we do not quantize the embedding, language model head, or activations. Additionally, we use symmetric quantization for consistency in our comparisons. It’s worth noting that our Spectra suite is designed with flexibility in mind, allowing for easy extension to other quantization methods as needed.
Training Dynamics and Scaling Laws
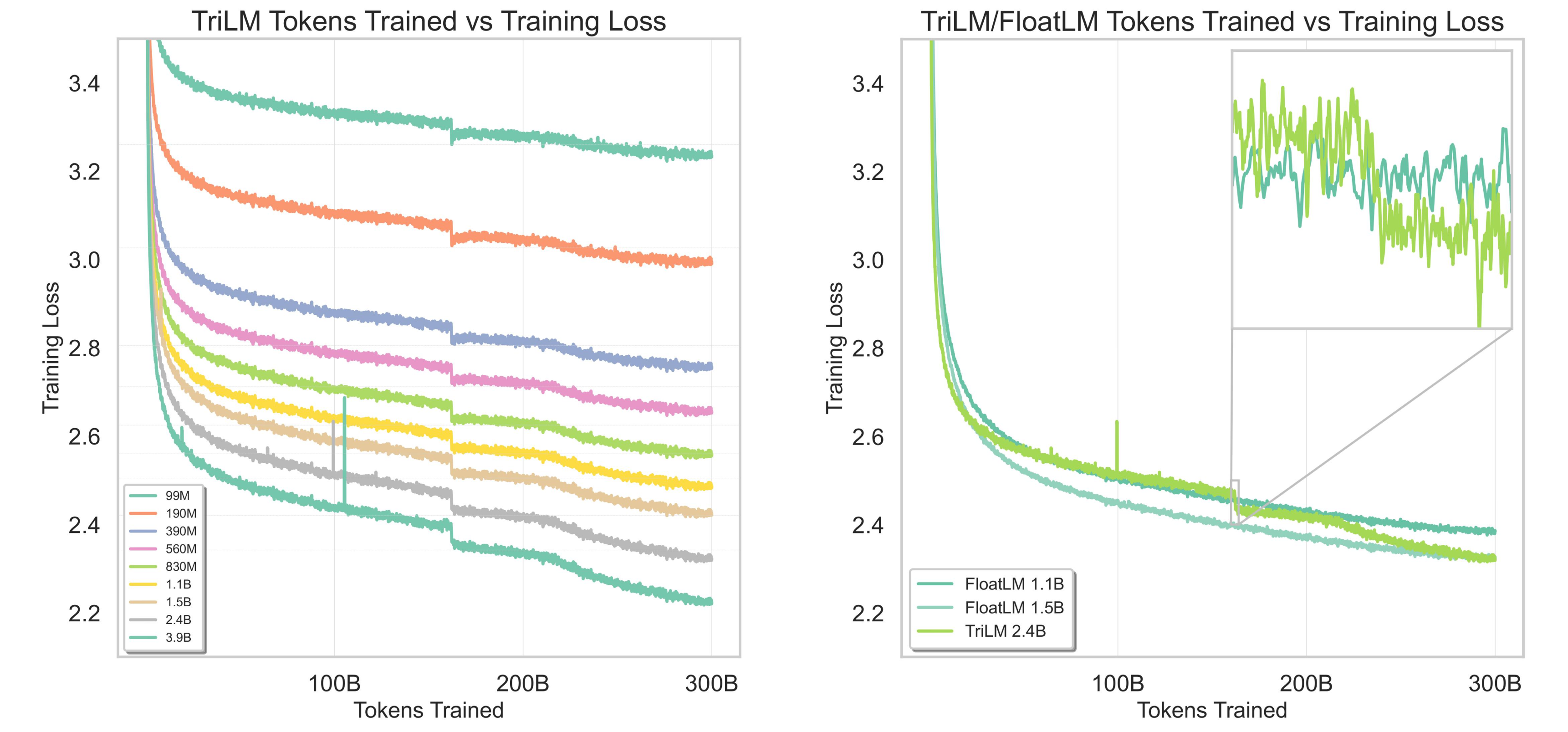
Above figures on left shows the training loss curves for all the TriLMs trained and figure on right shows relative training loss of a TriLM to two smaller FloatLMs. The loss curves demonstrate a continuous and consistent improvement in TriLMs with increase in parameter count. Furthermore, since the TriLMs were all trained on same data, with same ordering, minor spikes and drops in training loss are consistently observed at all scales at a given token count. It should be noted that the two largest models - TriLM 2.4B and TriLM 3.9B also showcase one large spike in training loss each in the first half of training. Upon dropping the peak learning rate at halfway point, a sharp drop (spanning over a course of only a few hundred million tokens) in training loss is observed. While, for the larger TriLMs (2.4B and 3.9B), rate of decrease in loss after this sudden drop reverts back to the same as before halfway-mark, it plateaus for the smaller ones (1.1B and 1.5B). In fact, for TriLMs with less than a Billion parameters, training loss starts to increase after this. At two-thirds mark, when weight decay is removed, all models start to converge faster, and this is most pronounced for the largest TriLM models.
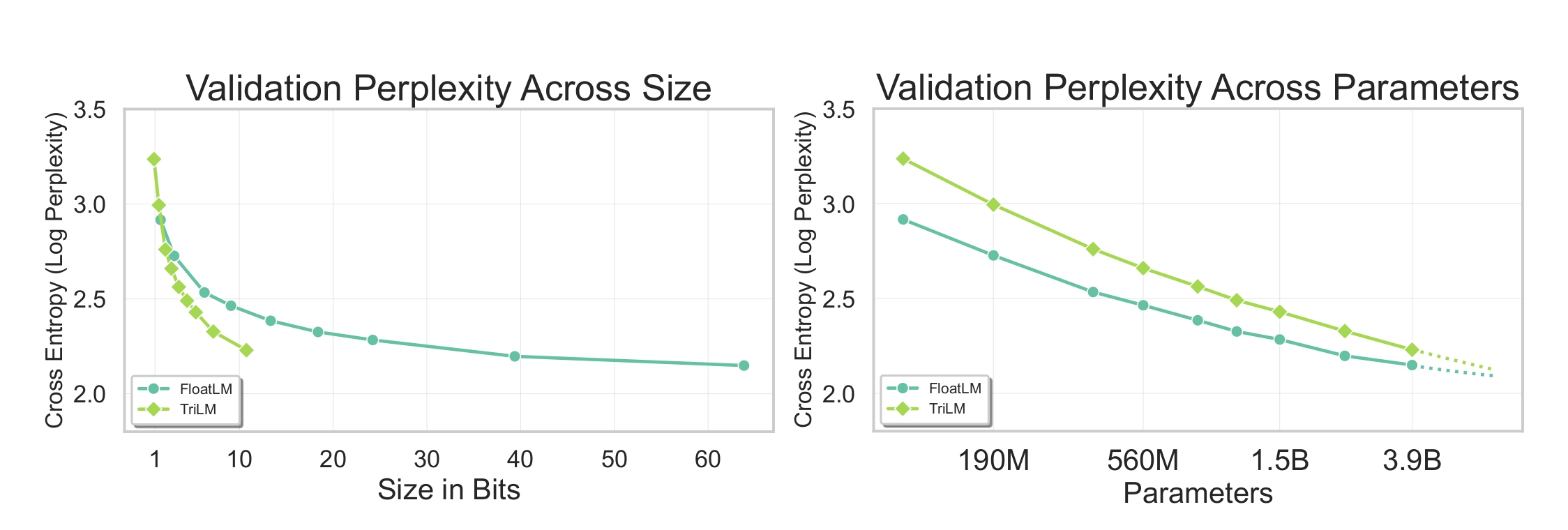
Figures above show the final validation loss across size (in bits) and across parameters respectively. When measuring performance in terms of size (crucial for output generation phase of inference), TriLMs, with increasing size, offer much better performance at same number of bits. Specifically, at the size of TriLM 3.9B, these ternary models start offering better performance than models more than five times their size. The scaling laws for FloatLM and TriLM up to the 3.9B parameter scale have been studied, and FloatLMs are clearly a better choice. However, the difference between the two considerably narrows at Billion + parameter scale and the trends shows the potential for TriLMs to meet (or even outperform) FloatLMs of same parameter count. Despite the gap in validation loss, we will later observe that TriLMs offer competitive downstream performance with FloatLMs of same parameter count across a variety of benchmarks in commonsense & reasoning and knowledge based tasks.
Evaluation
Commonsense and Reasoning
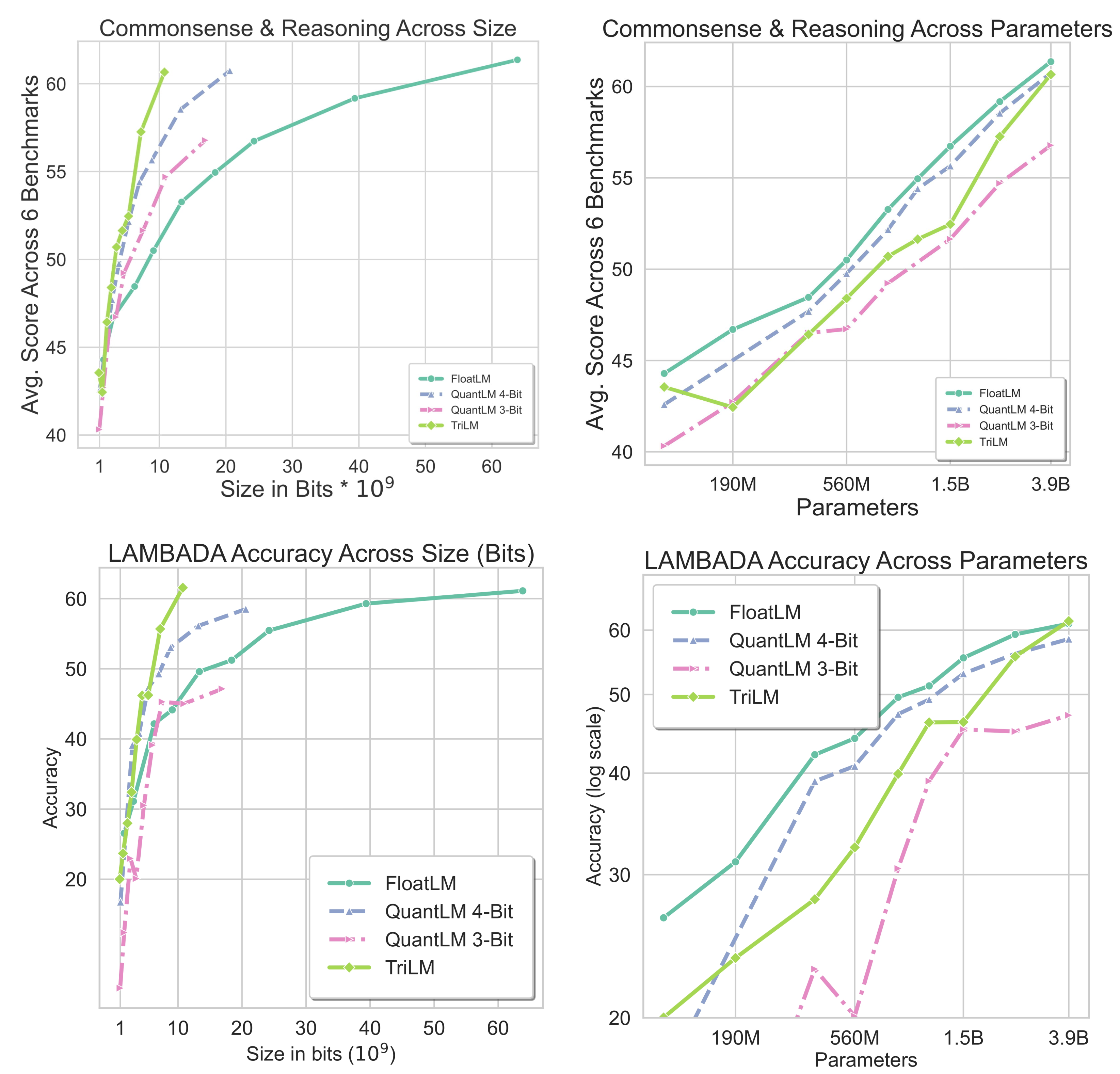
We assess the models using eight distinct commonsense and reasoning benchmarks consisting of tasks from logical and reasoning question to grounded and physical commonsense tasks: Arc Easy, Arc Challenge, BoolQ, HellaSWAG, WinoGrande, PIQA, LAMBADA, LogiQA, all under zero-shot settings.
Figures above on Common Sense and Reasoning shows the average performance of the LLMs on first six benchmarks (the same benchmarks as those reported for BitNet b1.58) across size (bits) and params. Figures below on the LAMBADA benchmark present the performance for the LAMBADA dataset. TriLMs consistently demonstrate superior performance for their size across all benchmarks at the 2.4B and 3.9B parameter scales. At the largest scale of 3.9B, TriLM surpasses FloatLM on LAMBADA and achieves competitive average scores across six benchmarks. Additionally, TriLMs at the largest scales consistently outperform 4-bit QuantLMs of equivalent parameter count.
Knowledge
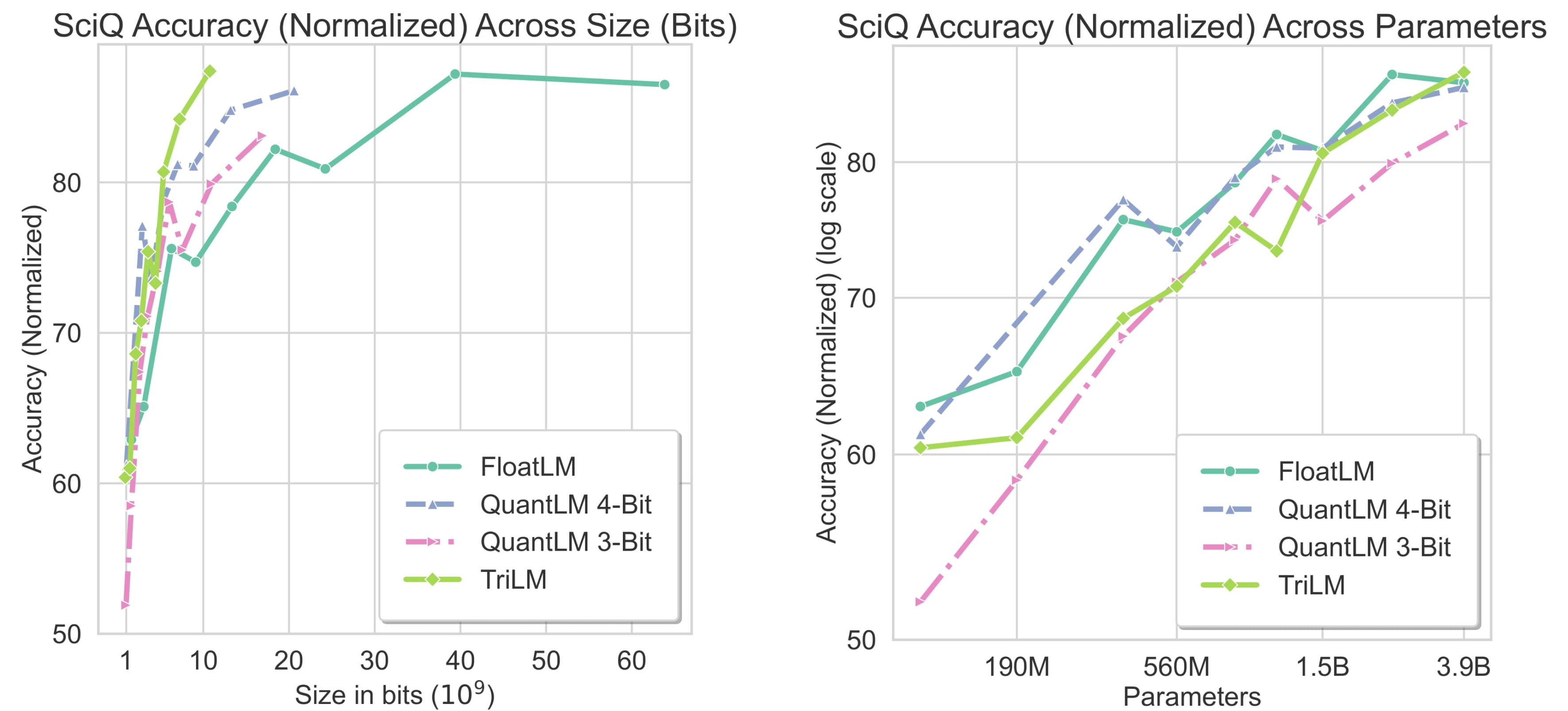
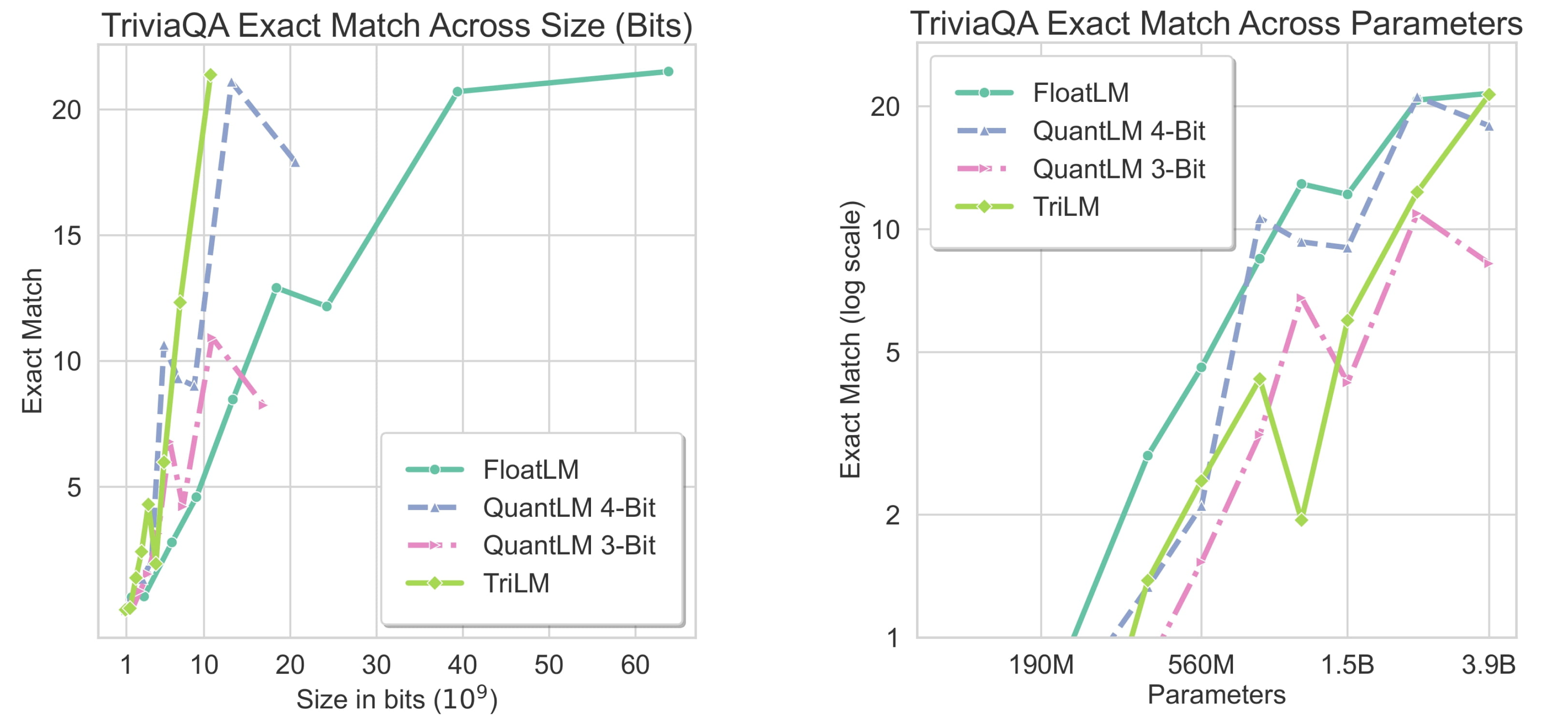
Several downstream practical uses of LLMs requires LLMs to have knowledge about common subjects like science or topics like political figures. We evaluate the performance of LLMs on SciQ, TriviaQA in zero-shot settings. Across both the benchmarks, at large 2.4B+ scales, TriLMs offer the best performance at a given size (bits). Surprisingly, despite having fewer bits, the knowledge capacity of TriLM do not have any significant degradation as observed in case of QuantLMs. Low-bitwidth LLMs like TriLMs have similar knowledge capacity to FloatLMs, indicate that knowledge capacity is parameterized via presence and nature of a connection (+1 or -1), rather than its strength.
Performance on SciQ and TriviaQA
Below are graphs showing the performance of the ternary TriLM, FP16 FloatLM, and quantized QuantLM (3-bit and 4-bit) models on the SciQ and TriviaQA tasks across size (bits) and parameters.
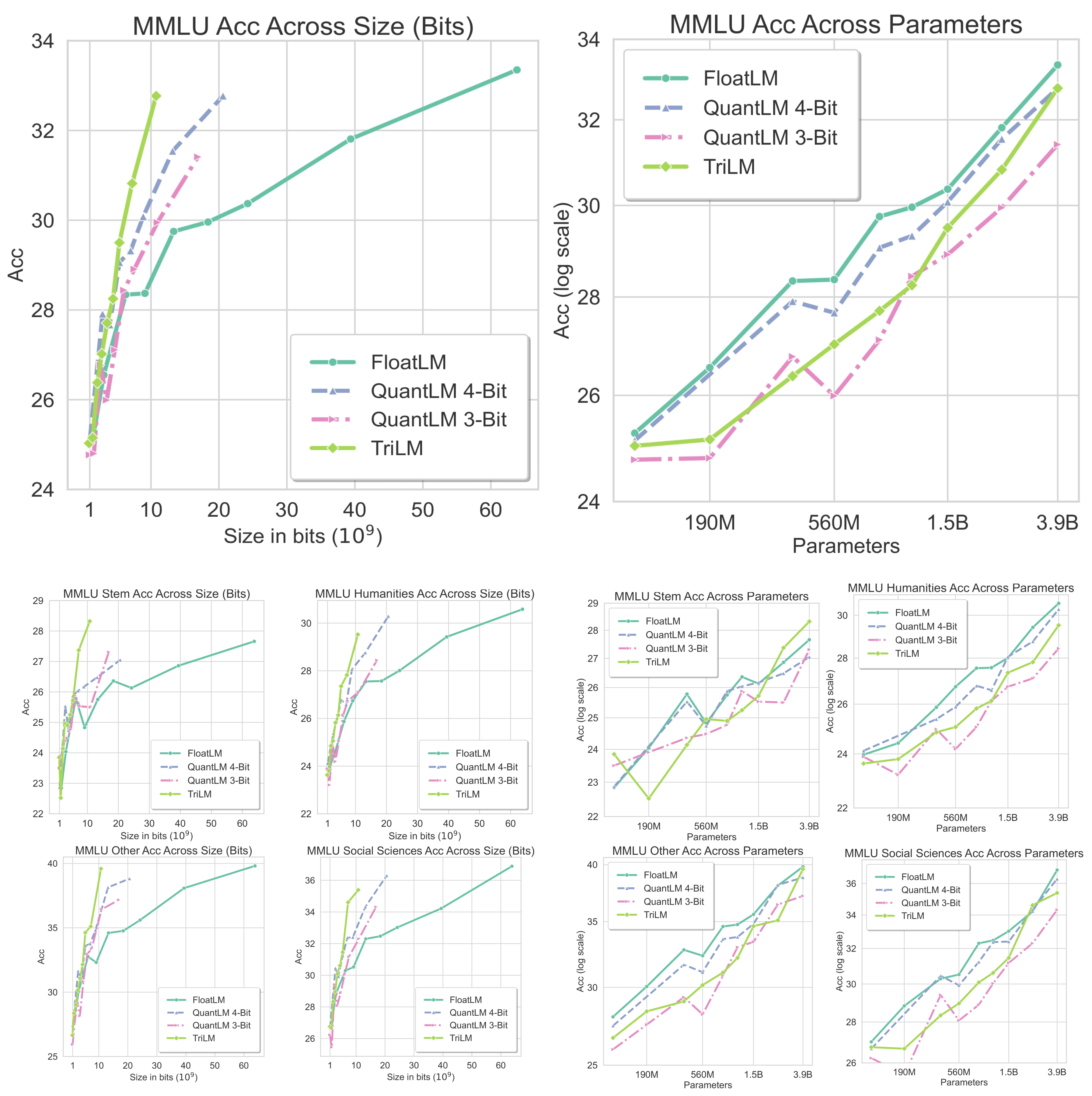
Performance on MMLU
MMLU Accuracy for ternary TriLM, FP16 FloatLM and quantized QuantLM (3-bit \& 4-bit) models across Size and Parameters
Conclusion
In this blog, We introduce the Spectra suite, an open family of LLMs across varying bitwidths, consisting of ternary LLMs (TriLMs), FP16 LLMs (FloatLM) as well as their quantized QuantLMs (3, 4, 6 and 8 bits) all pretrained on same 300B tokens of data. We also present our improved and simplified TriLM architecture for ternary language modeling that offers stable training at FP16 precision. Our evaluation of these models demonstrate that low bitwidth language models like TriLMs offer better performance for their size than quantized models at Billion+ parameter count. The TriLM 3.9B specifically achieves competitive performance to FloatLM 3.9B (a model much larger than TriLM 3.9B) across various benchmarks of commonsense & reasoning and knowledge based tasks. These results underscore the potential of TriLMs in addressing bottlenecks in LLM inference, stemming from memory capacity and bandwidth, better than QuantLMs.
Discussion
Interpretability Beyond Neuron Level: Traditional interpretability efforts in language models have focused on neuron-level interventions. TriLMs introduce a new dimension by enabling connection-level interpretability. In TriLMs, connections between neurons in a layer are in one of three states: 0 (no connection), -1 (negative connection), and +1 (positive connection), each with equal strength. This contrasts with FloatLMs, where connections vary in strength, complicating interpretability. By releasing checkpoints from our training runs, we encourage research in this direction.
Environmental and Resource Efficiency Benefits: Our open release of TriLMs reduces future emissions by eliminating the need for pretraining from scratch. TriLMs require fewer resources to deploy and can perform autoregressive generation faster, crucial for applications with strict latency requirements. Additionally, TriLMs enhance performance on resource-constrained edge devices, including smartphones, laptops, and automobiles.
Impact on Specialized Hardware: TriLMs offer significant memory reduction and latency improvements on general-purpose GPUs like H100 and RTX4090. Specialized hardware, such as Cerebras, which supports high byte-to-flop ratio computations, can leverage ternarization sparsity for speedups in both training and inference. Hardware with limited SRAM, like Groq, can reduce the number of required chips for deployment, thanks to the model size reduction.
Reduced Training Costs: Chinchilla scaling laws suggest that training larger LLMs for fewer tokens is more compute-optimal than training smaller LLMs for more tokens. However, memory and latency requirements for deploying larger models have led to costly training runs beyond Chinchilla optimality. TriLMs, with their reduced memory and latency needs, encourage more compute-efficient training runs with parameter-token tradeoffs closer to Chinchilla laws.
Acknowledgements
We acknowledge the support from the Mozilla Responsible AI Grant, the Canada CIFAR AI Chair Program and the Canada Excellence Research Chairs Program. This research was enabled by the computational resources provided by the Summit supercomputer, awarded through the Frontier DD allocation and INCITE 2023 program for the project “Scalable Foundation Models for Transferable Generalist AI” and SummitPlus allocation in 2024. These resources were supplied by the Oak Ridge Leadership Computing Facility at the Oak Ridge National Laboratory, with support from the Office of Science of the U.S. Department of Energy. We extend special thanks to Jens Glaser for his assistance with the Summit and Frontier supercomputers.
Citation
If you find these blog, models or the associated paper useful, please cite the paper:
@misc{kaushal2024spectracomprehensivestudyternary,
title={Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models},
author={Ayush Kaushal and Tejas Pandey and Tejas Vaidhya and Aaryan Bhagat and Irina Rish},
year={2024},
eprint={2407.12327},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2407.12327},
}