We at Nolano.AI are extending most capable open-source LLMs to new domains, languages and use cases.
Abstract
While GPT-4 and similar models achieved impressive performance, primarily in the English language, state-of-the-art (SoTA) language models for many other languages still need to be built.
We, introduce Hi-NOLIN, with the goal of building the first state-of-the-art open-source English-Hindi bilingual model. We build upon the Pythia model suite, starting by expanding 7B Pythia architecture to a 9B model. This allows us to scale more efficiently on our hardware (6 GPUs per node instead of 8). We trained this on the 300B token Pile text corpus, which contains both English and code data, and continued pretraining the model on a dataset combining both Hindi and English, in order to extend the model’s ability to understand and generate Hindi language.
We observe that, when using the several best practices for continual training, such as, model learning rate re-warming and data replay, we not only transfer and expand LLM’s capabilities to a new language (despite relatively small training data available in that language) but also improve on the original training language and domains (such as English and Code). For example, our continually trained 9B parameter model already outperforms a larger 12B Pythia model, while expanding its capabilities to Hindi. This contrasts with recent efforts of extending LLMs such as LLaMa to new domains such as code (Code LLaMa) and German language (LeoLM), which typically comes at the cost of reduced performance in original domains (the phenomenon known as “catastrophic forgetting” in continual learning).
Below, we showcase the current progress of our ongoing training for the Hi-NOLIN-9B model - a checkpoint at the 600B tokens on the new training dataset that contains Hindi. We also observe the Bilingual model to generalize to Code-Mixed English-Hindi informal language of Hinglish - a popular mixed language currently spoken by over 350 million people.

Introduction:
Hindi is one of the most widely used languages, spoken by more than 600 Million people. It has a rich ancient history, deeply ingrained in culture and reflected in a large amount of literature. However, no open-source high-quality Hindi LLM was built so far, perhaps due to the relative scarcity of data available for training such models from scratch.
To overcome this issue, our we continually train our Hindi model on top of the existing open-source LLMs that were pre trained primarily on English language, aiming to extend the capabilities of those models to the new language without forgetting the one learned before, and without having to incur the excessive cost of training such model from scratch on a large iid dataset containing mix of Hindi with the other pre-training data those models were already exposed to. However, previous works leading to models such as CodeLLaMa (which extended LLaMa for code generation) and LeoLM (which extended LLaMa for German Language) demonstrated that extending model to new domain comes at a cost of lower performance on original domain - the issue called “catastrophic forgetting” in continual learning literature - even with optimizer re-warming up.
Current Achievements:
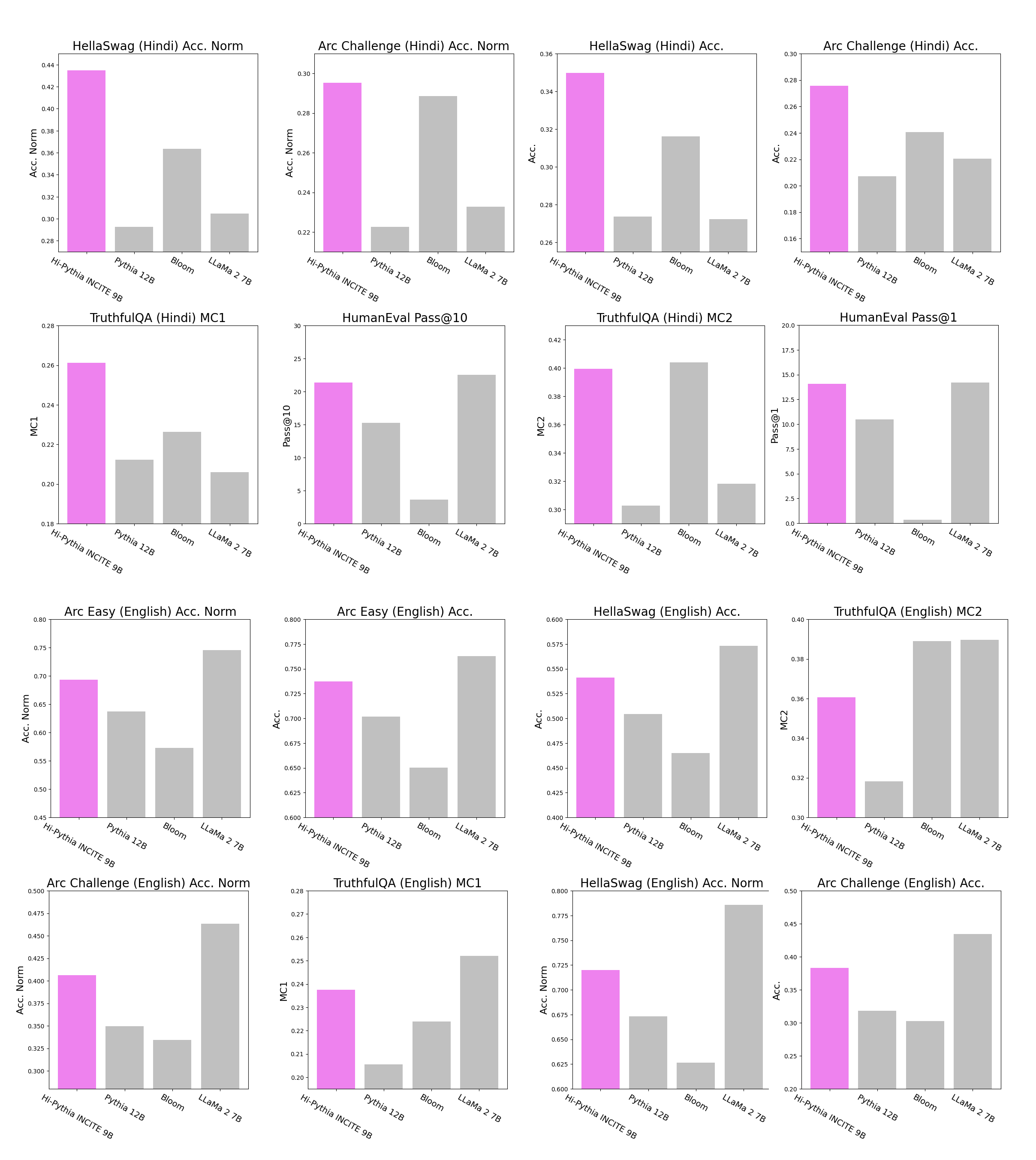
We built the best open-source Hindi-English LLM of its size, which strongly outperforms all models of comparable sizes, such as Pythia 12B, LLaMa-2 and multilingual BLOOM models across various standard LLM Evaluation benchmark, including HellaSwag, ARC Reasoning Challenge and HellaSwag in the Hindi language.
Our model extends ability to a new language while further improving performance on English and Code domains. Continual pre training also improved the performance of the model on English domain, where it already starts to significantly outperform a larger 12B parameter Pythia model and closes the gap with the 7B LLaMa-2 across the TruthfulQA, ARC Easy, ARC Challenge and HellaSwag benchmarks for English languages. Similar trend - i.e., improved coding abilities - was observed when using the HumanEval benchmark in Python programming language.
Improved Code and English performance while extending to a new language:
Continual pre training over pythia also improved performance in English domains of the model, where it starts to significantly outperform larger Pythia 12 Billion parameter model and closes the gap to LLaMa 2 model across the TruthfulQA, ARC Easy, ARC Challenge and HellaSwag for English languages. Similar trend of improved coding abilities is observed over the HumanEval benchmark in Python programming language.
Model and Training Details
We are currently still in the process of training Hi-NOLIN, and present below preliminary results on only 600B tokens with model no-where close to converging. The Hi-NOLIN’s network architecture was somewhat modified from the Pythia to ensure maximum training resource utilization over the unusual configuration of 6 GPUs per node (Summit supercomputer). We leverage several excellent pytorch open source projects of GPT-NeoX, Megatron-LM and DeepSpeed to train with 3D parallelism and ZeRO redundancy optimizer, utilizing 3072 GPUs across 512 nodes. We assume that the optimizer state after pre-training is not available for continual training, similar to prominent open-source models like LLaMa and Mistral. So we reinitialize it and consider the re-warming schedule of (Gupta et al, 2023.
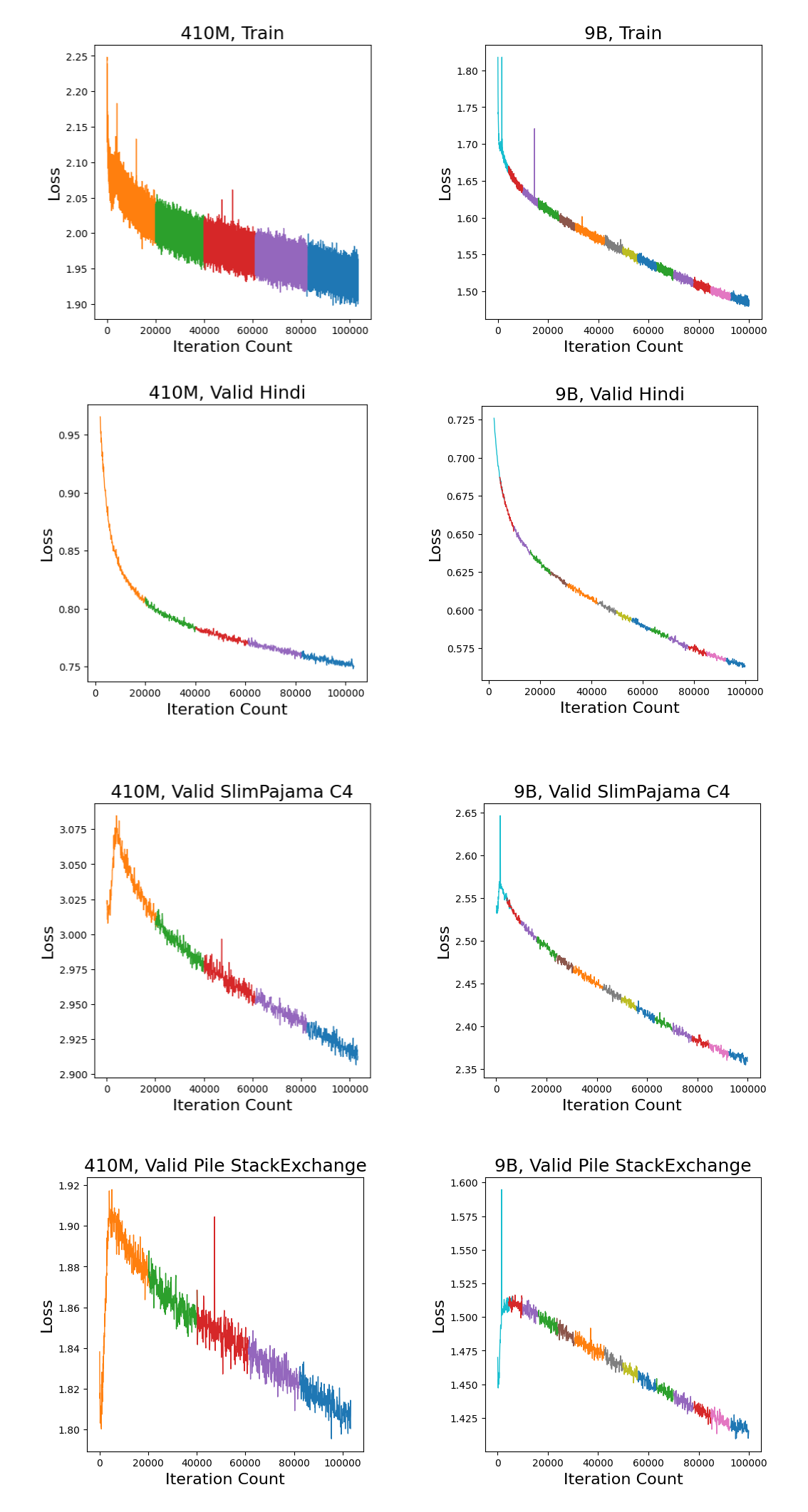
Our 9B model shows practically steady reduction in training loss, as well as in Hindi validation loss, with relatively low variance (loss spikes), and is clearly still far from convergence, promising further significant improvements - in contrast with the 410M model. Note that, while the validation loss for English initially increases, it eventually achieves far lower validation loss.
Benchmarking
We are using several standard LLM benchmarks, such as HellaSwag, TruthfulQA, Arc and Human Eval, for measuring the performance of Hi-NOLIN across Hindi, English and Code. Note that Hi-NOLIN is already showing better performance than Pythia 12B and multilingual Bloom at 600B across almost all evaluation benchmarks and closes the gap with LLaMa 2 models.
Few-shot examples.


Contact us?
If you have questions or requirements related to the training, continual pretraining, or finetuning of large language models, or if you have any suggestions, we would be eager to hear from you. Please email us at hello@nolano.ai
Join Our effort
Nolano is actively seeking talented full-stack developers, both full-time and interns to join our growing team; if you’re interested, please reach out to us at hello@nolano.ai. Additionally, consider joining the INCITE AGI project Discord for collaboration and insights.
Release:
The model will be released under Apache 2.0 license at https://huggingface.co/nolanoAI/Hi-NOLIN-9B
The Team Behind Hi-NOLIN
- Ayush Kaushal (Remote consultant at UdeM)
- Tejas Vaidhya (Student at UdeM and MILA )
- Irina Rish (Prof at the University of Montreal)
Acknowledgements
The model’s training is conducted using 3,072 GPUs provided as a part of the INCITE compute grant on Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF), the DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725. This grant was awarded to AAI CERC lab at Université de Montréal, LAION and EleutherAI for their Scalable Foundation Models for Transferrable Generalist AI project. We are grateful for the invaluable support provided to us by the OLCF leadership and by the OLCF liaison for the INCITE project.
We are also grateful to the INCITE project team, and especially Kshitij Gupta and other contributors to the Continual Pretraining of Foundation Models project. Our work builds on top of this team’s work on continual pretraining of Pythia models. Many thanks to Quentin Anthony (EleutherAI and INCITE project team) for porting DeeperSpeed and the GPT-NeoX training framework to Summit, and providing insights on the design Pythia 9B model for maximizing training resource utilization
References
Biderman, S., et al. (2023). Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling arXiv:2304.01373. arXiv preprint arXiv:2304.01373.
Gupta, K., et al. Continual Pre-Training of Large Language Models: How to (re)warm your model? arXiv:2308.04014. arXiv preprint arXiv:2308.04014.
Rozière, B., et al. Code Llama: Open Foundation Models for Code arXiv:2308.12950. arXiv preprint arXiv:2308.12950.
Rajbhandari, S., et al. (2020). ZeRO: Memory Optimizations Toward Training Trillion Parameter Models arXiv:1910.02054. arXiv preprint arXiv:1910.02054.
Andonian, A., et al. (2023). GPT-NeoX: Large Scale Autoregressive Language Modeling in PyTorch (Version 2.0.0) [Software]. https://doi.org/10.5281/zenodo.5879544
Gao, L., Tow, et al. A framework for few-shot language model evaluation (Version v0.0.1) [Software]. Zenodo. https://doi.org/10.5281/zenodo.5371628
BigScience Workshop, et al. (2023). BLOOM: A 176B-Parameter Open-Access Multilingual Language Model arXiv:2211.05100. arXiv preprint arXiv:2211.05100.
Touvron, H., et al. (2023). Llama 2: Open Foundation and Fine-Tuned Chat Models arXiv:2307.09288. arXiv preprint arXiv:2307.09288.
Plüster, B. (n.d.). LEOLM: Igniting German-Language LLM Research. LAION. Retrieved from https://laion.ai/blog/leo-lm/